Drupal QueryPath 1.1 Module Released

Today the QueryPath 1.1 Drupal module has been released. This module provides Drupal developers with access to the QueryPath library. In addition, it integrates Drupal's database library with QueryPath, making it possible to execute Drupal database queries and feed the results directly into QueryPath.
This module will be useful to Drupal developers who deal with XML content. No more ugly DOM code -- or worse, hand-built parsers created using PHP's XML Parser library (a wrapper on the aged xpat). Now you can query any XML or HTML document using CSS 3 selectors of XPath queries. You can also retrieve XML from remote sources simply by passing the URL to QueryPath's qp() factory function.
QueryPath can be used in any the following ways (plus more, of course):
- Import data from XML or HTML files.
- Use web services.
- Parse remote RSS and ATOM feeds.
- Interact with Twitter, Flickr, and other REST/XML-based services.
- Format database results for display.
- Template complex data from databases, XML, or other data sources.
- Use SPARQL and query the semantic web.
- Remove PHP code from existing HTML files.
Included with the Drupal QueryPath module is an additional module containing some examples. Here are a few of those examples explained. We will begin with something easy.
- If you want to start at square one, without having to meld Drupal and QueryPath knowledge, you should probably begin with The Tutorial. This will get you oriented to the basics of QueryPath.
Querying the Drupal Database from QueryPath
The first thing we will see is how to perform a simple database query from QueryPath, and then inject the results into the HTML output. The Drupal QueryPath module has a number of helper functions which expose Drupal database tools to QueryPath.
<?php
function querypath_examples_show_sticky_nodes() {
// The SQL query: select node titles for all nodes that are sticky.
$sql = 'SELECT title FROM {node} WHERE sticky = 1';
// Create a new UL list, run the query, and for each title, add it as a list item.
return qp('<?xml version="1.0"?><ul></ul>')
->query($sql) // Run the query
->withEachRow() // With every row...
->appendColumn('title', '<li/>') // Append the title to the UL as a list item (LI)
->top() // Go back to the top of the document (the UL)
->html(); // Get the whole thing as HTML.
}
?>
The function above is used as a regular menu callback. In a nutshell, here's what it does. It queries the node table in the database and retrieves the titles of all sticky nodes. (In a standard Drupal build, sticky nodes are the nodes that stay on the front page.)
For each row that it finds, it adds the title as an LI on an unordered list. Then the resulting HTML is returned. If you run the version of this that is included in the example module, which contains the above code plus some help text, you will see something like this:
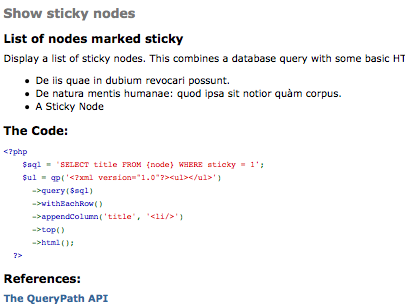
Of course, this is just an example. More robust documents can be created this way. By combining the power of SQL as a database query tool and QueryPath as an HTML manipulation tool, you can create complex displays in concise and clean code. (QueryPath has a standard database library that you can use, too.)
Using Twitter's XML API
The popular Twitter social networking platform publishes a complete REST/XML API. QueryPath can use this rich API to interact with Twitter. The Twitterpated and TweetStock tools both use QueryPath to do this.
Similar tools can be integrated into Drupal using the QueryPath module. For example, here is an example menu callback function for Drupal that uses QueryPath to query the Twitter public timeline and display the most recent tweets.
<?php
function querypath_example_show_twitter() {
// This is going to the the output: A simple UL list:
$ul = qp('<?xml version="1.0"?><ul/>');
// This is the URL we will contact. We could pass arguments in either a GET or POST context,
// but we don't need to here.
$url = 'http://twitter.com/statuses/public_timeline.xml';
// This is the HTML template we will populate for each tweet we receive. There
// are several ways of templating with QueryPath. We are using a sorta Drupalish
// method.
$tpl = '<li>
<div style="height: 55px">
<img style="float:left" src="@img"/>
<strong>@uname</strong><em>@ts</em><br/>
@txt
</div>
</li>';
// This loop will retrieve data and then loop through the data returned.
// The foreach loop does a lot. First, it uses the qp() method to query the remote server.
// Using the CSS 3 element selector ('status'), it retrieves all <status/> elements. Since a
// QueryPath object is iterable, we can loop through it and perform a task on each status
// element.
foreach (qp($url, 'status') as $status) {
// Next, we build up an array to pass to strtr.
$data = array();
// Get the 'created_at' element and convert it to a suitable time format.
$data['@ts'] = date('d m Y', strtotime($status->children('created_at')->text()));
// Get the text, username, and user image.
$data['@txt'] = $status->next('text')->text();
$data['@uname'] = htmlentities($status->parent()->find('user>screen_name')->text());
$data['@img'] = $status->next('profile_image_url')->text();
// Use strtr to populate the template.
$data = strtr($tpl, $data);
// Append the item (an LI) to the UL.
$ul->append($data);
}
// Transform the UL into an HTML fragment (as a string)
// and return the results.
$out .= $ul->html();
return $out;
}
?>
The code above might look complicated, but in fact it is quite straightforward. All we are really doing is querying the remote server for the Twitter public timeline and then looping through the results, formatting each for display. Most of the calls above simply fetch bits of data out of the XML data and format them.
So what does all of this look like when it's rendered? Here's a screenshot of the example module's Twitter output. (Disclaimer: This is just some random shot of the public twitter feed.)
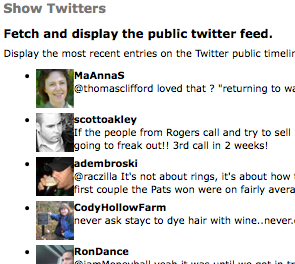
This code illustrates three things:
- How QueryPath can be used to fetch remote data and parse it.
- How XML and HTML can be traversed.
- How multiple QueryPath objects can work together to transform one source of data into another.
Other Examples
There are two other examples in the Drupal QueryPath module that you might find of interest.
One of them reads the RSS feed generated by Drupal and creates a list of links. This illustrates simple XML retrieval and simple templating.
The other uses QueryPath in combination with the Forms API (FAPI) to illustrate how users can submit data which may then result in queries to a remote server. It queries the MusicBrainz server to find out information about artists and the albums they produce. Here's a screenshot of this last one in action.
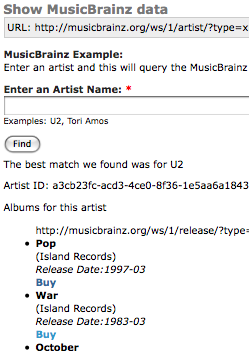
The QueryPath module is a versatile tool. While it shares much in common with the jQuery library that inspired it, QueryPath diverges. It is built for server duty, and it provides a robust set of features for dealing with local and remote data. Best of all, though, is that it can be extended easily. Need a new QueryPath tool? Simply write a little bit of code to attach your feature to QueryPath.



