Saved by the Bug
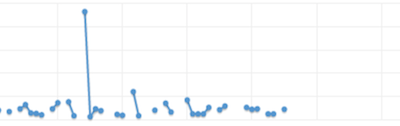
We should have seen a catastrophic failure. The server should have gone down in flames. But instead, we just saw these little blue blips. This is the story of how the effects of a dire and destructive bug were forestalled by... a little tiny bug.
It all started when we noticed something odd on AWS CloudWatch. Several days after deploying a major version upgrade of our server, little blue dots started appearing in our load balancer reports. These were BackendConnectionError incidents. We'd never seen these in development or in staging, and the Amazon documentation on backend connection errors is a little sparse. All we could glean from them was that the load balancer was having trouble establishing a connection with our app servers. Something was breaking, but we had no idea what.
Forensics, Round 1
Of course, we hit the usual metrics.
- CPU: Fine
- Memory: Fine
- Logs: Nothing unusual
- Disk IO: Low
- Database Latency: Low
- External services: Fine
- Network Traffic: Fine
I even wrote a special tool, tcptimer to test certain kinds of network issues. But alas, nothing.
In fact, the only indications of an error were the little blue dots on the Cloud Watch report. They seemed to follow no particular pattern, though we saw them happening more frequently as the server ran longer. The perceived worsening of the situation was really all we had to go on.
Round 2, In Which We Learn About Goroutines
We hadn't seen the errors on development or staging. So maybe it had to do with load.
I decided to add some lower-level instrumentation to the app server and run a local load test. I configured my local instance to periodically dump lots of information about the memory usage. Since the server is written in Go, I looked at the runtime package for documentation on runtime.ReadMemStats. While there, I saw there were a couple other easy things to instrument for, including goroutines.
In Go, a goroutine can be thought of as a lightweight thread. While we knew fairly well how we use goroutines in our applications, I figured I'd instrument these anyway, since it was easy and might give some hint or indicator.
With the instrumentation done, I started up the server. The initial metrics looked something like this:
2014-06-24 19:50:53 info:76c0b38e METRICS: goroutines: 9, cgo: 40, alloc: 7377040, totalAlloc: 54761416, heapAlloc: 7377040
That looked pretty normal. Then I ran the acceptance tests. And the first surprise hit: goroutines was up to 250. And it didn't go down. Another run of the tests, and the number of goroutines as nearing 400. The server performed fine, of course. Go is very efficient. Still... why were goroutines piling up like that?
With a little quality time digging through stack traces, we had our answer: One of the libraries we use was leaking goroutines pretty badly. Fortunately, none used much memory. But unfortunately that turned our app into a ticking time bomb. And under production load, it's anyone's guess how long it would be before it exploded.
Of False Alarms and Real Alarms
Nothing rushes a release out the door faster than the "ticking time bomb" metaphor, and we had this thing in QA in two shakes of a bunny's tail. The fix we implemented worked flawlessly, and our load tests (fortified with metrics) looked pretty darn good.
There was this nagging sense of doubt...
But for sure, we knew that the consequences of not deploying this fix could be grave indeed.
And so we deployed it. And so it went into production. And so we refreshed the CloudWatch graph over and over again. And so the little blue dots didn't go away.
We'd fixed a major bug, and we all knew it. But... but... but everything seemed to be exactly the same. "And by the way," we said, "If this crazy thread leak had been the problem, surely we would have seen the CPU spike!" In fact, that's precisely what we should have seen. We should have seen our servers all go down in flames.
A quick calculation yielded a startling number: just over 3 million goroutines (threads) should have been running on our server. Go is cool, Go is robust, Go is powerful... but on our paltry single-core app servers, the VMs should have locked up tighter than a state penitentiary.
Something else was amiss.
Round 3: Everything's Better in a New Version
As we tossed around ideas we got to talking about Go 1.3's new features. It was released about a week ago, and one of the things it provides is the ability to log certain HTTP errors that before may have slipped from the server logs.
Wait... were there messages that were slipping from the server logs? We log everything! With religious fervor! But could something have missed our net?
So we went a-hunting. Thankfully, Ubuntu's upstart logs stderr to a file for us, and sure enough, we found some low-level errors that had bypassed the server logs altogether.
And lo, the darkness was removed from our eyes, and we saw. We saw that the server had been hitting a fatal error condition, and was quietly restarting. And it all made sense. For a moment or two after each restart, the server was unavailable. But not enough so that the load balancer health checks failed. Instead, it was just a little blue blip on a graph.
The fatal error turned out to be a really dumb mistake on my part, and we fixed it in a moment. And as soon as it was deployed, the blue dots vanished.
Conclusion, or Breaking Stuff is Hard to Do
As I drove home that night, the reality of the situation sunk in. The goroutine bug, had it hit with full force, would have been catastrophic. It probably would have killed our app servers within a few hours of each launch. And it would have led to rolling complete outages for our customers. Buried deep in a third-party library, it would have evaded the kind of digging we normally do during an outage or emergency. Certainly we would not have had this leisurely week of log watching and thoughtful debugging. In short, it would have been terrible.
But that dumb little bug that caused the restart saved the day. By periodically restarting, it effectively kept our thread pool small and prevented the goroutine bug from ever really having any consequence at all. And paired with the load balancer, the bug managed to shield our customers from any inconvenience whatsoever. As far as we know, not a single customer noticed.
We were saved... by a bug.



