A CI/CD Implementation for the Cloud Age
Drone, Packer, Ansible, Docker... we associate a litany of names with continuous integration and continuous deployment. But when it comes to building a toolchain that seemlessly transitions our applications from a developer's editor to a running server, we often have to rely on our wits.
My team has invested heavily in building an awesome CI/CD system based entirely on top-shelf open source tools. Here's what our solution looks like.
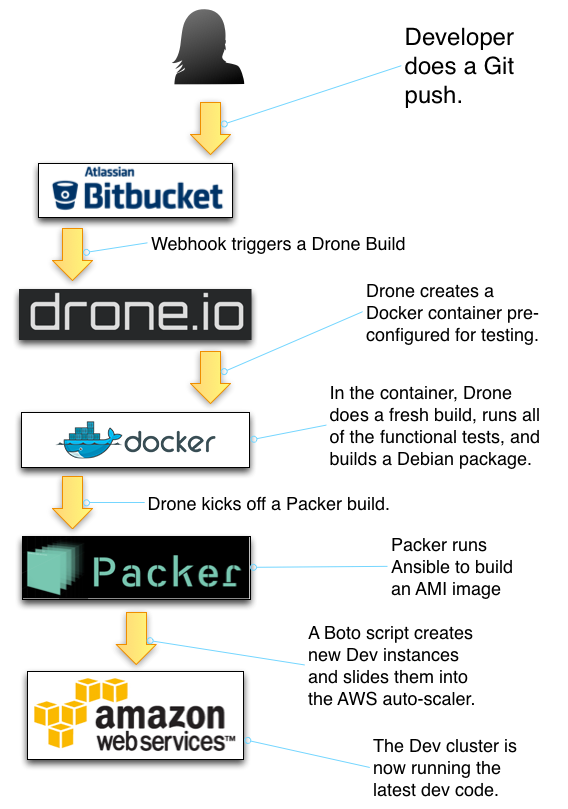
In the rest of this post, I'll explain how the model above fits our needs, and (at a conceptual level) how it works.
Our Needs
For our cloud services, we needed a general system that could take a Git commit and move it through the process of compiling, testing, packaging, and releasing. Following a more traditional model, we deploy continuously to a Dev server, but our production releases are carefully timed with the other components of our total system (e.g. We update the cloud portion a few days before the mobile apps go live).
Our development and production environments dictated some key facets of our deployment methodology:
- We store our code in Bitbucket.
- Our production servers are all hosted EC2 instances in AWS (with load balancers and autoscaling).
- Because our target release platform is Linux, but many developers work on OS X, it is imperative for us that we run pre-release integration tests in an environment that closely resembles production.
- Releases should be zero-downtime and we should be able to roll back to previous versions at any time.
On these initial requirements, we began building a deployment environment.
A Few False Starts
We tried out a few methods that did not work out well for us. Here are a few of the notable ones:
- Elastic Beanstalk: Amazon's Elastic Beanstalk service is really cool, and we have used it for rapidly prototyping tools as well as launching internal services. But the finer points of deployment made the EB a poor fit for our production services.
- Jenkins: We dove deeply into Jenkins. But it was just too cumbersome for our needs. We needed better resource isolation, simpler configuration of basic tasks (like Debian package installation), and a better place to store our valuable configuration data than in textareas on a web form.
- Fabric: Ultimately, we did decide to use Python Fabric for some of the steps in our process. But our initial attempt to build an entire CI/CD tool from Fabric scripts just didn't work.
Our Solution
As you can see from the diagram above, we finally decided on a system that used the following components:
- Bitbucket
- Drone
- Docker
- Packer
- Ansible
- Fabric
- Boto (a Python AWS library)
- Goose (a database migration manager)
At first, the list looks daunting, but most of these we just used as they are.
For any given project, there's a .drone.yaml file to edit, some Packer/Ansible
work, and possibly a fabfile (Fabric's equivalent of a Makefile) to tie it
all together.
We broke things down like this:
- Each project has its own
.drone.ymlandfabfile. The Drone YAML file tells Drone what to do with the project, and the Fabricfabfileserves the dual purpose of providing local builds and telling Drone how to execute a remote deployment. - Projects that use an RDB also provide their own Goose migration scripts (which are just SQL DDL files.)
- A central DevOps codebase handles all of the rest of the code. Notably, our Ansible playbooks and Packer configuration go there.
The big diagram above shows how code progresses through the system.
- First, a developer pushes to the Bitbucket Git repository.
- Drone listens to each repo for commits. When it receives a commit, it creates
a new Docker container (according to our
.drone.ymlconfig) and fires off the build steps defined in.drone.yml. - We often have Drone also create helper containers, like a PostgreSQL database, so that we can run real integration tests, including Goose database migrations and real tests of transactions.
- Once tests have passed, Drone will build Debian packages (.deb files), version them, and deploy to our Apt repository. While it was a pain to set up the first time, we love having every version of our code versioned and easily installable on any Ubuntu Linux system.
- The last thing Drone does with this special Docker container is kick off a Packer build. Packer's job is creating an EC2 AMI (machine image) totally pre-configured with our application.
- Packer spins up a builder running a fresh copy of Ubuntu Linux.
- Packer then runs its built-in Ansible to provision our environment. It installs
all of the security updates, creates some configuration files for us, and tunes
the environment to handle our load. Finally, Ansible uses
apt-getto install the project's Debian package. - Once the machine image has deployed, we have a simple Boto script that
creates several EC2 instances based on our shiny new AMI. Once these are up
and running and passing healtchecks, the boto script does three things:
- Add the new instances to the ELB load balancer
- Configure autoscaling to use our new AMI
- Once all health checks are passing, remove the older instances and just keep the new ones.
By that point, we have a running dev instance.
Production Deployment
So how do we get this stuff to production? Actually, it's easy. We just run the last three steps of the above, but for our production environment. After all, that process is tested each and every time we do Git push, so we have a high degree of confidence that if it works for dev, it will work for prod. We have a straightforward Fabric script for launching these deployments.



