The Snooty Developer's Visual Guide to Kubernetes
With its own vocabulary and architecture, Kubernetes can seem downright scary. To tame the beast, I give you a simple visual (and snarky) guide to Kubernetes concepts.
Don't look here for nitty gritty implementation details. For that is not the way of the Kubernaut. We are platonists, concerned not with the ways of the imperfect world, but in the contemplation of the celestial spheres. So we will set about charting the way of the Kubernetes application developer.
And Lo, There Was An App
As developers, we're all pretty comfortable with the starting point of this discussion. We start with an app. Let's say that our app is a web application. Let's say that it's a PHP app, and that it's all packed into one PHP file:
<?php
echo 'Hello World';
?>
Here's a diagram of our puny little app.
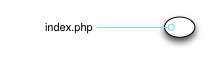
It is small, but not because the app is unimportant. It's just that we're going to need a lot of space as we chart out the Kubeosphere. (NB: Real Kubernauts can prepend "Kube" to an arbitrary suffix and sound cool.)
Our poor little PHP app cannot run on its own. It needs a webserver.
The App's Environment
The webserver isn't really part of the app's code. It's part of the app's environment. For that matter, so is the file system and the environment variables and the shell, and so on. But let's keep it simple, and just talk about the webserver.
Our app runs inside of the web server, so we can chart it out like this:
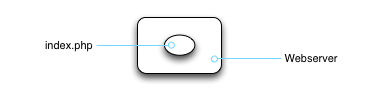
Here's where Docker comes into the picture. Once upon a time, we ran webservers as privileged applications inside of a full operating system. One OS might be running dozens upon dozens of applications, and part of the system administrator's job was to keep all of those applications working properly inside of a shared environment without trampling all over each other.
This is not the way of Plato. We don't like our implentations to be cluttered and gross. We desire crystalline perfection. We want containers.
Containers
Solaris introduced an interesting method of segment applications into separate zones, each with its exclusive filesystem (but sharing the same kernel resources). While Solaris's implementation never really caught on, when Linux implemented a similar system, the Docker project provided a bootstrapping layer that made it super easy to build and manage containers.
While Docker is clearly to blame for a plethora of really bad shipping puns and whale iconography, it is the default basis for running apps in Kubernetes. (If you don't like whales, you might try rkt [rocket], which also builds containers, but with space puns instead of mammals with submersive tendencies.)
So we'll run our web application in its very own container -- a container that has just the necessary files for our webserver and app.
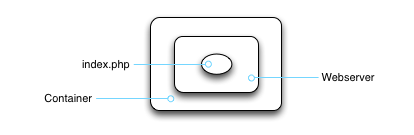
Somewhere under our container is a base operating system that is handling all the mechanics of passing information to and from our container. And while it's easy to run a container, it's a pain in the butt to manage this others stuff. There are network bridges and bind-mounted filesystems and cgroups and whale jokes, all of which must be attended to.
While managing that stuff by hand is a virtual root canal, Kubernetes can do it for you. And it does this by running your container (or maybe a couple of your containers, if you please) inside of a pod. Please, for the love of all that is good, resist the temptation to make jokes about "pods of whales."
Pods
In Kubernetes, a Pod is a logical wrapper around two or more tightly coupled containers. Now, I say two because every pod has a hidden container that basically holds resources. But most of the time, we just pretend that it's not there, and we say that a pod holds an application, which usually fits into a single container.
So our application-in-a-server-in-a-container-in-a-pod looks like this:
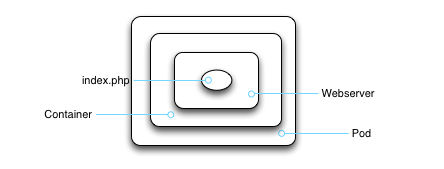
Now, if we were to regress to the olden days, we'd talk about how a pod ran on a node, where in Kubernetes a node is basically the server that hosts the pod. But one of the design goals of Kubernetes is to keep dirty little implementation details like that far, far away from you, the Platonic res cogitans. No, we don't care about which host or hosts our pod is running on. We care only about how our beautiful app can realize it's Eidos (that's Plato-talk for intellectual perfection) within the cloud.
What we really care about, when it comes to our web app, is that we can scale it up, handle more traffic, update it with no downtime, and even handle a crash. So really, we shouldn't concern ourselves with pods, but with the a group of pods.
Replication Controllers (RCs)
Kubernetes has a way of grouping pods together into a nice little cluster. This little cluster can scale up (dynamically create extra pod copies), or scale down (remove a few copies). It can monitor each and every little pod, and if one is misbehaving or unresponsive, it can kill that one and bring on a suitable replacement.
In Kubernetes, all of this is done with replication controllers, usually just called RCs. An RC describes the resources that an application needs in order to run as a cluster of pods. Instead of creating pods ourselves, we just give the RC a pod template, and let it clone pods like they were sheep in a geneticist's lab.
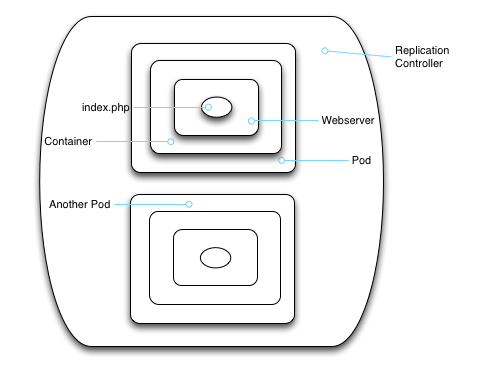
Now here's the thing about pods: If you've used Docker before, you know that containers are considered--let's be frank--expendible. That's why you don't get to name your pods in an RC.† Kubernetes generates a cold, impersonal, usually unpronounceable pod name for you so that you don't develop irrational emotional attachment to your pods. As the saying goes, we don't love our containers like pets. We treat them like cattle. Pods, too, are cattle. They are resources that we assume won't be around too long.
A Note To Vegans: You should probably treat your pods like soy beans, not cattle.
But that gives us a pair of problems. The first is that if a pod is disposable, we need to figure out a way to make the currently living pods available to the outside world, yet without letting the outside world get attached to them. To put it plainly, our web app wouldn't be all that easy to use if the URL changed constantly. But we do need to pipe requests for the website from the outside world all the way to a pod that can handle the request.
The second problem is that we need a way to store data, because we don't necessarily want our data to go away every time a pod goes away. So Kubernetes provides a couple of tools to help us.
† Actually, naming of pods has nothing to do with petishness. But it does have everything to do with cold, calculated rationality.
Services
A service provides the permanent part of the network side of things. For example, a service preserves IP addresses and ports so that DNS names can map to the same thing. The pods associated with a service may come and go, but the service provides a stable interface to the world.
Like pets, you can name your service, and you can keep them around for a long, long time. Unlike pets, you can't pet your service.
And now that we have services, we can also start to see how network traffic gets routed (conceptually) into Kubernetes. Inbound traffic comes into Kubernetes, earmarked for the service. Kubernetes handles routing that traffic back to the actual pod or pods that will respond to the inbound request.
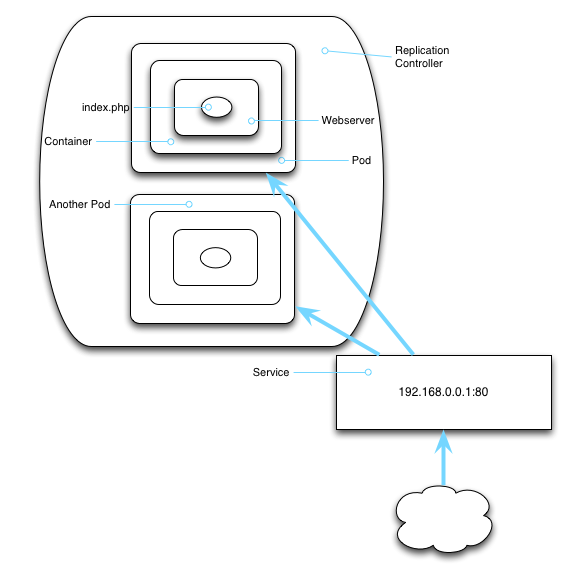
In this diagram, a service gives us a consistent IP address that will be there for the long haul (until we delete it or Kubernetes gets nuked). And so we can safely map DNS names to the service, or hook up a load balancer to that IP.
(For those of you who are not good platonists, the service is really more of a definition than an operational component. Behind the scenes, routing is done by a smattering of supporting technologies, including IP tables, virtual IPs, and some fancy proxies. But we shall not sully our beautiful diagrams with the mundane.)
Volumes
Along with stable networking resources, apps might need a place to store data that lives longer than a pod. In keeping with our platonic heritage, we don't want to think in terms of actual disk drives. And our ephemeral pods can float like dryer lint from node to node. We certainly don't want to cramp their style by tying them to a particular node's local filesystem. Ideally, a pod should not give one wit about which node it's running on. In fact, if our pod wants to be a little skeptic and not even believe in nodes, we should just be okay with that.
What we need is a way to say that we need data storage, and then just have data storage. That is exactly what Kubernetes provides (well, with some provisios, some quid pro quos...). Kubernetes' name for these is Volumes.
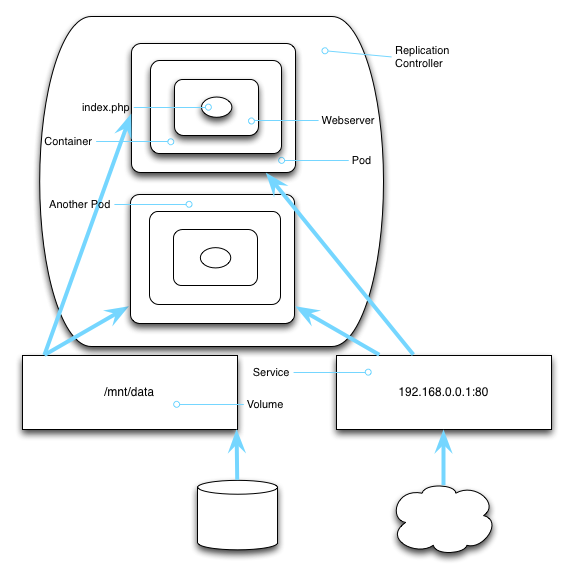
To a container running in a pod, a volume just magically appears mounted into the file system. It will show up as a regular old directory, and all the regular file operations work. With the volume service, containers running inside pods can transparently access persistent storage.
Now, if I were to step down from my ivory tower and soil my hands with the details of this, I'd point out that...
- Volumes are actually backed by something. It might be an AWS ELB, or a GlusterFS cluster, or even a git repo (No kidding. It's in the code! I Swear!).
- Different volume types don't always behave the same. Some can be mounted to only one container while others can be shared. And performance varies by backend.
- Sometimes they are (cough) erm... that is to say... um... read only.
- And... well... actually... there are a few that aren't even persistent.
Fortunately, as good platonists, we don't have to clutter up our diagram with such stuff and nonsense. Instead, we can turn our faces toward the heavens and ascend to the highest sphere.
Namespaces
Kubernetes can run tens, nay hundreds, nay thousands of pods (and soon, even more). But most of us don't have that many applications to deploy. On the other hand, as we learned in Kindergarten, sharing is nice, especially if you can get rid of the carrot sticks and gain a vanilla wafer or two.
So Kubernetes provides a way of encapsulating all your stuff -- your pods and replication controllers and services and volumes -- all into one really big globule of... well... stuff. And that big overarching grouping mechanism is called a namespace.
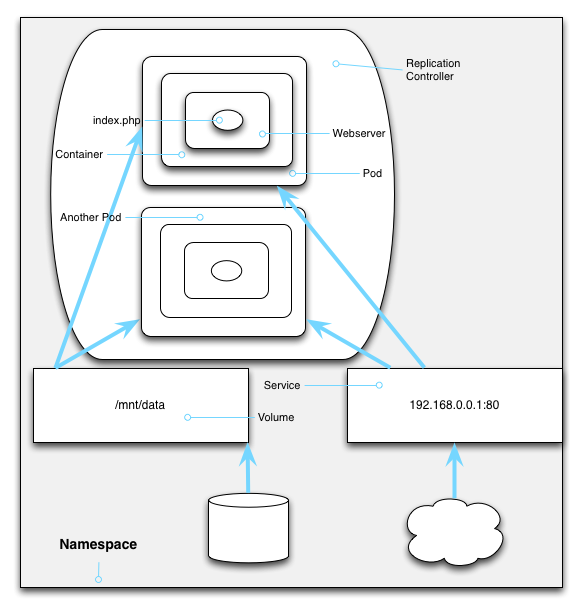
The namespace isolates your set of stuff from everybody else's stuff. Inside your namespace, your pods can easily discover each other. Outsiders, on the other hahnd, have to be told how to connect to your stuff. And on an administrative level, you can manage things in your namespace without knowing or caring about the stuff in other namespaces.
Concussion
And that is the turducken that is Kubernetes. While the concepts and terminology present a formidable mental hurdle, the platform itself is powerful and elegant. Instead of tarring and FTPing your application like you did in the Stone Age, now you can focus on just writing your app. And a writing a Dockerfile. And a service definition. And an RC definition. And volume definitions.
We developers can spend our time in rapt contemplation of the idealized app, in it's idealized containers, pods, volumes, services, and replication controllers.
Meanwhile, on the other side of the platonic firewall, a swarm of rabid DevOps engineers are busy messing with haproxy, kubelets, IP Tables, and Ceph -- a gaggle of services you don't even have to know about. Don't feel bad for them. As Plato pointed out, it is the job of the Philosopher (that's you) to contemplate the cosmos, while the Hoi Polloi find their meager joys in writing systemd unit files and writing Salt provisioners.
That is what makes Kubernetes great.



